一种深度学习技术可为实时2D动画生成实时口型同步
实时二维动画是一种相当新颖而强大的交流形式,它使人类表演者可以实时控制卡通人物,同时与其他演员或观众互动和即兴表演。最近的例子包括史蒂芬·科尔伯特(Stephen Colbert)在《后期秀》中采访卡通客人,荷马在《辛普森一家》(The Simpsons)的一段节目中回答观众的现场电话提问,阿切尔(Archer)在ComicCon上与现场观众交谈,以及迪斯尼的《星际大战:邪恶力量》和My Little Pony通过YouTube或Facebook Live与粉丝主持实时聊天会话。
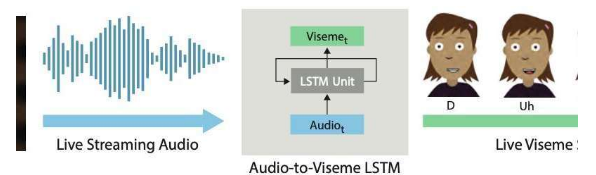
制作逼真的,有效的实时二维动画需要使用交互式系统,该系统可以自动将人类表演实时转换为动画。这些系统的一个关键方面是获得良好的口型同步,这实质上意味着动画人物的嘴巴在说话时会适当移动,模仿在表演者的嘴巴中观察到的动作。
良好的口型同步可以使实时2D动画更具说服力和功能强大,使动画角色可以更真实地体现性能。相反,不良的口型同步通常会破坏角色作为现场表演或对话参与者的幻觉。
在最近的论文预先公布的上的arXiv,两位研究人员在研究的Adobe和华盛顿大学推出了深基础的学习互动系统,可自动生成分层2 d动画人物活唇音同步。他们开发的系统使用了长期短期记忆(LSTM)模型,一种递归神经网络(RNN)架构,该架构通常应用于涉及对数据进行分类或处理以及进行预测的任务。
“由于语音几乎是每个实时动画的主要组成部分,因此我们认为在这一领域要解决的最关键的问题是实时口型同步,这需要将演员的语音转换为动画角色中相应的嘴部动作(即视位序列)。在这项工作中,我们致力于为实时2D动画创建高质量的口型同步。”进行这项研究的两位研究人员Wilmot Li和Deepali Aneja通过电子邮件告诉TechXplore。
Li是Adobe Research的首席科学家,拥有博士学位。计算机科学领域的一位学者,他一直在计算机图形学与人机交互的交叉点上进行广泛的研究。另一方面,Aneja目前正在完成博士学位。她是华盛顿大学计算机科学与图形图像实验室的成员。
Li和Aneja开发的系统使用简单的LSTM模型,以每秒24帧的速度将流音频输入转换为相应的视位音素序列,并且延迟不到200毫秒。换句话说,他们的系统允许动画人物的嘴唇以与人类用户实时说话类似的方式移动,而声音和嘴唇移动之间的延迟小于200毫秒。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
试驾极狐阿尔法S(ARCFOX αS)是一次令人印象深刻的体验。从咨询开始,品牌的专业客服迅速回应了我的疑问,...浏览全文>>
-
如果您想预约哈弗猛龙的试驾体验,可以按照以下步骤快速在4S店完成预约:首先,您可以通过哈弗汽车的官方网站...浏览全文>>
-
如果您想体验零跑汽车的试驾服务,可以通过以下步骤在4S店快速预约:首先,访问零跑汽车的官方网站或通过其官...浏览全文>>
-
试驾奔驰迈巴赫S级的预约流程简单清晰,以下是具体步骤:首先,访问奔驰官方网站或联系当地授权经销商。在网站...浏览全文>>
-
纳米01试驾流程通常包括以下几个步骤:第一步:预约试驾用户可以通过品牌官网、4S店或电话预约试驾。提前预约...浏览全文>>
-
奔腾B70是一款集时尚设计与卓越性能于一身的中型轿车,近期有幸对其进行了一次深度试驾。这款车型不仅外观大气...浏览全文>>
-
想要快速预约福特蒙迪欧的试驾体验驾驶乐趣?以下是一些简单步骤帮助您轻松完成:首先,访问福特官网或通过福...浏览全文>>
-
大众试驾,轻松搞定试驾想要深入了解一款车的性能与驾驶感受?试驾是最佳选择!无论是追求操控感的运动型轿车...浏览全文>>
-
试驾现代胜达时,您需要满足一些基本条件以确保安全和顺利的体验。首先,您必须持有有效的驾驶证,并且驾龄通...浏览全文>>
-
小鹏G7是一款备受关注的智能电动车,对于新手来说,试驾前需要了解一些关键步骤和注意事项,确保安全且充分体...浏览全文>>
- 哈弗猛龙预约试驾,如何在4S店快速预约?
- 零跑汽车试驾,如何在4S店快速预约?
- 江淮iEV7试驾预约预约流程
- 试驾MG4 EV全攻略
- 奥迪SQ5 Sportback预约试驾,线上+线下操作指南
- 全顺试驾预约,一键搞定,开启豪华驾驶之旅
- 魏牌预约试驾全攻略
- 试驾零跑汽车零跑C01,畅享豪华驾乘,体验卓越性能
- 试驾哈弗H6操作指南
- 零跑T03试驾,畅享豪华驾乘,体验卓越性能
- 菱势汽车预约试驾,轻松搞定试驾流程
- MINI试驾,线上+线下操作指南
- 试驾沃尔沃XC60,从预约到试驾的完美旅程
- 试驾QQ多米,畅享豪华驾乘,体验卓越性能
- 试驾丰田汉兰达,一键搞定,开启豪华驾驶之旅
- 力帆预约试驾,一键搞定,开启豪华驾驶之旅
- 阿维塔12预约试驾,4S店体验全攻略
- 试驾江铃E路顺V6,简单几步,开启完美试驾之旅
- 灵悉L试驾预约,如何享受4S店的专业服务?
- 极氪7X试驾,如何享受4S店的专业服务?