您现在的位置是:首页 >市场 > 2021-04-06 22:12:13 来源:
IBM可能驯服AI企业?
人工智能还没有准备好应对“业务流程”。消息从国际商业机器本周在一份研究报告提供了从蓝色巨人IBM Watson和阿尔马登研究中心的科学家们单位。
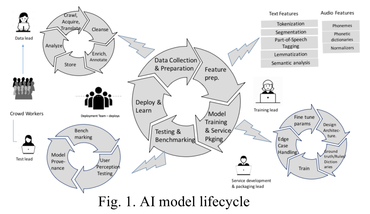
本文提出了大量的充满希望的建议,但也意味着大量的问题是否AI太不守规矩的,目前野生蓝色巨人来驯服它。IBM的研究人员的建议是,很多机器学习阶段需要考虑仔细,包括一个经理应该如何“设定目标”的神经网络模型中,“数据管道”应该如何构建的示例作为神经网络的输入,以及如何不断“迭代”人工智能模型来改进它。
特别关注的是事情监管的行业,如数据的“血统”:什么是数据的“合法性”被使用?
本文描述机器学习过程:一个成熟的框架,发布在预印arXiv服务器上,并由拉玛Akkiraju Vibha Sinha,安邦,塔拉马哈茂德,Pritam Gundecha,哲刘,刘,和约翰•舒马赫。
人工智能的挑战,为企业之间的本质区别是机器学习编程和传统的软件编程,IBM说:“虽然传统软件应用程序是确定的,机器学习模型是概率。”此外,神经网络开发使用“混乱的数据,”事实不完全适合企业。
还:IBM推出工具检测AI公平、偏见和开放来源一些代码
没有做任何关于这个的,IBM说:“学术文献在机器学习模型未能解决如何让机器学习模型为企业工作。”
达到一定程度的成熟更适合企业使用,IBM的科学家提出将机器学习符合广大文学在“应用程序生命周期管理”等,而这些术语的含义延伸到符合小说的AI质量。
具体地说,研究人员利用Watts Humphrey, 1980年代,定义了软件能力成熟度模型。CMM是一种地图软件的阶段在一个组织。它开始于“不成熟”阶段,当公司没有控制它是做什么用的程序,和总结快乐的阶段,一个组织能够不断“优化”项目。
工作的最原始的贡献是神经网络研究人员的建议,应该着眼于开发特定行业的特殊性。发现人工智能的“业务用例”,他们写道,可能需要公司“定制通用机器学习模型与行业、领域,和用例具体的数据使他们更准确的具体情况。”
IBM显然是冒险进入一个灌木丛的棘手问题。机器学习的有很多方面,特别是在它的深度学习化身,不能轻易和解的整洁规范的能力成熟度模型。
例如,IBM提出一个“人工智能服务数据会导致“公司内监督,一开始的工作,什么样的“地面实况”的标签附加到数据的机器。但“无监督机器学习试图远离地面实况在神经网络的设计。
另外:IBM研究人员提出人工智能服务透明度文档
同样,一个组织内的“培训主管”应该是处理数据在神经网络发展的“特征提取”阶段,包括诸如想出“分词器。”再次,深度学习的大部分是关于自动特征提取,而不是这种手工工作。
也许最令人生畏的前景是企业,在IBM的看来,应该是负责确保偏见的神经网络是免费的,整个人工智能社区的一个任务挠挠头。之间的职责”提供经理,负责开发的神经网络,是“确保模型是免费的不受欢迎的偏见,公平、透明。”
最后,虽然在他们的建议作者表现的很自信,好像机器学习可能太粗野的蓝色大提供了的期望。
当他们写报告的结论:“犹豫在采用人工智能模型的另一个原因是组织发现黑盒和非透明。特别是模型与深度学习技巧训练。”
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")