您现在的位置是:首页 >要闻 > 2020-10-26 11:19:29 来源:
决定下一步行动的机器人需要优先级帮助
随着机器人在诸如搜索和救援任务等危险情况下替代人类时,它们需要能够快速评估并做出决策-像人类一样做出反应和适应。伊利诺伊大学香槟分校的研究人员使用了基于“夺旗”游戏的模型来开发深度强化学习的新方法,以帮助机器人评估其下一步行动。
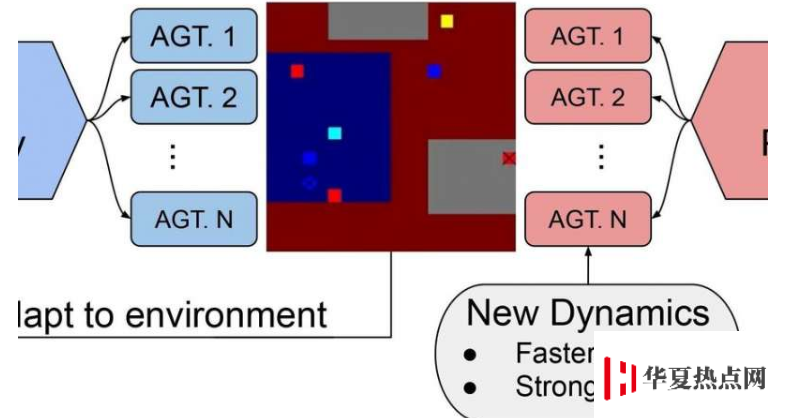
研究人员之所以选择“夺旗”,是因为它是由两个团队(每个团队有多个队友)组成的,对手的团队也在做出决定。
研究员Huy Tran表示:“机器人可以通过一种名为强化学习的试验和错误过程来学习如何在竞争性游戏等环境中做出反应。他们可以通过玩游戏来了解在给定情况下应采取的行动。”在UIUC的航空航天工程系。“挑战在于弄清楚如何创建也能适应意外情况的代理。”
Tran说,他的团队意识到机器人在确定任务优先级时需要帮助。
“考虑到捕获标志的总体任务,实际上我们有一个子任务可以完成,我们在一个层次结构中进行建模。我们想探索的是这种类型的层次结构是否会有助于适应。”
通过分层的深度强化学习,Tran表示任务被拆分了—夺取旗帜或标记对方团队的成员以消除它们—因此该模型可以处理更复杂的问题。
“通过将任务分解为子任务,我们可以改善适应性。我们培训了一位高级决策者,他为每个代理分配了子任务以供其关注。” 特兰说。Tran说,分层结构有助于简化模型的更新。仅层次控制器将需要更新,而不是每个代理都需要更新。
“这种方法有可能解决有趣且具有挑战性的问题,但是在现实环境中部署这些系统之前,我们仍然需要解决许多问题。例如,我们了解到该框架可以帮助适应”,Tran说,“但我们认识到,在这项研究中,我们根据对游戏运行方式的直觉决定了子任务应该是什么。这并不理想,因为它有我们自己的偏见。我们现在要做的是寻找新的技术,使代理商能够自己弄清楚那些次目标是什么。”
Neale Van Stralen,Seung Hyun Kim,Huy T. Tran和Girish Chowdhary撰写了研究“评估分层深度强化学习的适应性能”。该研究由美国国防高级研究计划局资助,并在2020 IEEE国际机器人与自动化会议(ICRA)上发表,并在会议记录中发表。一段简短的视频说明了包括分层控制器在起作用的工作。
")









")
")
")
")
")
")
")
")
")