科学家使用机器学习来优化油井的水力压裂设计
水力压裂实质上是在高压下将流体泵入储层的过程,这会产生裂缝,并帮助将碳氢化合物带到井中,并最终带到地表,这是增产油气的最广泛使用的技术之一。在过去的几十年中,HF的技术复杂性日益增长,以至于现在需要进行广泛的设计和使用复杂的多模块模拟器进行预先建模。
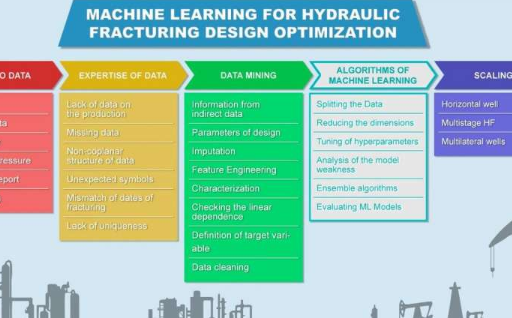
“与此同时,将这些模拟器的预测与现实联系起来仍然是校准,验证和验证真实数据模型的主要问题。此外,要闭合压裂模拟器和生产数据之间的循环,需要将压裂设计建模耦合在一起使用储层模拟器,这会进一步增加复杂性和不确定性。作为替代方案,我们决定正确看待压裂设计和生产的现场数据,这是成功的衡量标准。”多相系统实验室负责人Andrei Osiptsov教授解释说该研究的合著者是Skoltech碳氢化合物回收中心的成员。
M-阶段实验室的研究人员以及ADASE小组负责人Evgeny Burnaev教授领导的CDISE同事决定,看看基于机器学习的数据驱动的HF设计方法是否可以帮助应对这一挑战。
他们项目的关键部分始于2018年,是一个数字数据库,其数据涉及JSC Gazprom Neft周边俄罗斯西伯利亚西部约20个油田的约6000口井的压裂工作和石油生产。每个数据点包含油藏,井和压裂设计参数以及16个采油参数上的92个变量。
“我们设法收集并清理了一个很大的水力压裂完工数据库。通过将机器学习方法应用于该数据库,我们已经可以根据工艺参数准确预测水力压裂结果。我们仍然需要解决根据这一预测,为选择水力压裂工艺的参数而建立最佳建议的任务艰巨。”该研究的合著者本那夫教授说。
M-Phase Lab高级工程师兼项目经理,该研究的合著者Albert Vainshtein指出,由于真实数据的歧义性,高度不确定性和异质性,该项目“从一开始就非常具有挑战性”。
“我认为数字数据库的开发将使我们能够检验各种假设,进而可以清除压裂过程的多种隐藏模式。例如,重要的是确定在哪个注入的支撑剂吨位上我们的累积油量。生产停止增长。根据条件,通常的方法是在每个压裂阶段注入60吨。使用机器学习模型和统计数据,我们可以证实或拒绝这种假设。” Skoltech博士Anton Morozov说道。M阶段实验室的学生和研究实习生。
科学家们已经根据他们的机器学习方法提出了试井压裂设计建议,并已提交给业界合作伙伴。他们希望即将进行的现场测试活动将展示其技术在石油生产中的潜力。不过,伯纳夫重申,“在描述水力压裂系统设计的输入数据中仍然存在大量不确定性”。在项目的下一阶段,他们旨在开发新的方法来估计这种不确定性。
“处理实地数据需要勇气和谨慎,因为它非常敏
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
试驾极狐阿尔法S(ARCFOX αS)是一次令人印象深刻的体验。从咨询开始,品牌的专业客服迅速回应了我的疑问,...浏览全文>>
-
如果您想预约哈弗猛龙的试驾体验,可以按照以下步骤快速在4S店完成预约:首先,您可以通过哈弗汽车的官方网站...浏览全文>>
-
如果您想体验零跑汽车的试驾服务,可以通过以下步骤在4S店快速预约:首先,访问零跑汽车的官方网站或通过其官...浏览全文>>
-
试驾奔驰迈巴赫S级的预约流程简单清晰,以下是具体步骤:首先,访问奔驰官方网站或联系当地授权经销商。在网站...浏览全文>>
-
纳米01试驾流程通常包括以下几个步骤:第一步:预约试驾用户可以通过品牌官网、4S店或电话预约试驾。提前预约...浏览全文>>
-
奔腾B70是一款集时尚设计与卓越性能于一身的中型轿车,近期有幸对其进行了一次深度试驾。这款车型不仅外观大气...浏览全文>>
-
想要快速预约福特蒙迪欧的试驾体验驾驶乐趣?以下是一些简单步骤帮助您轻松完成:首先,访问福特官网或通过福...浏览全文>>
-
大众试驾,轻松搞定试驾想要深入了解一款车的性能与驾驶感受?试驾是最佳选择!无论是追求操控感的运动型轿车...浏览全文>>
-
试驾现代胜达时,您需要满足一些基本条件以确保安全和顺利的体验。首先,您必须持有有效的驾驶证,并且驾龄通...浏览全文>>
-
小鹏G7是一款备受关注的智能电动车,对于新手来说,试驾前需要了解一些关键步骤和注意事项,确保安全且充分体...浏览全文>>
- 哈弗猛龙预约试驾,如何在4S店快速预约?
- 零跑汽车试驾,如何在4S店快速预约?
- 江淮iEV7试驾预约预约流程
- 试驾MG4 EV全攻略
- 奥迪SQ5 Sportback预约试驾,线上+线下操作指南
- 全顺试驾预约,一键搞定,开启豪华驾驶之旅
- 魏牌预约试驾全攻略
- 试驾零跑汽车零跑C01,畅享豪华驾乘,体验卓越性能
- 试驾哈弗H6操作指南
- 零跑T03试驾,畅享豪华驾乘,体验卓越性能
- 菱势汽车预约试驾,轻松搞定试驾流程
- MINI试驾,线上+线下操作指南
- 试驾沃尔沃XC60,从预约到试驾的完美旅程
- 试驾QQ多米,畅享豪华驾乘,体验卓越性能
- 试驾丰田汉兰达,一键搞定,开启豪华驾驶之旅
- 力帆预约试驾,一键搞定,开启豪华驾驶之旅
- 阿维塔12预约试驾,4S店体验全攻略
- 试驾江铃E路顺V6,简单几步,开启完美试驾之旅
- 灵悉L试驾预约,如何享受4S店的专业服务?
- 极氪7X试驾,如何享受4S店的专业服务?