您现在的位置是:首页 >要闻 > 2020-12-12 08:36:01 来源:
特工在捉迷藏游戏中表现出令人惊讶的行为
导读 研究人员在让他们的AI野心发挥出巨大的捉迷藏游戏中取得了令人震惊的结果。特工的环境有墙和可移动的盒子,用于挑战,其中一些是藏身者,而
研究人员在让他们的AI野心发挥出巨大的捉迷藏游戏中取得了令人震惊的结果。特工的环境有墙和可移动的盒子,用于挑战,其中一些是藏身者,而另一些则是寻找者。一路上发生了很多事,令人惊讶。
作者说到学到的东西后写道:“我们观察到代理商在玩简单的捉迷藏游戏时发现了越来越复杂的工具使用,”代理商建立了“一系列六种不同的策略和对策,其中一些我们不知道我们的环境支持什么。”
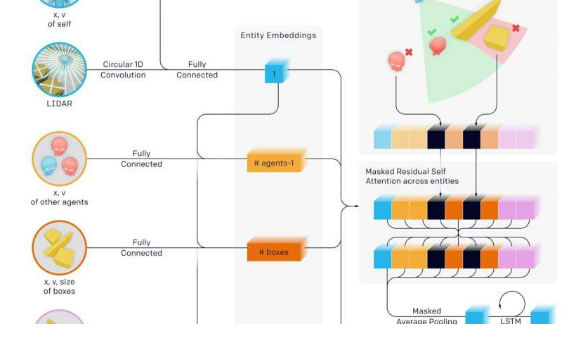
在本周早些时候发布的新论文中,该团队透露了结果。他们的论文“来自Multi-Agent Autocurricula的紧急工具使用”有7位作者,其中6位列出了OpenAI代表,一位是Google Brain。
作者评论了他们所面临的挑战。“创建可以解决各种各样与人类有关的复杂任务的智能人工代理,一直是人工智能界的长期挑战。”
该团队说:“我们发现代理创建了一个自我监督的自动课程,引发了多个不同的紧急策略回合,其中许多回合需要复杂的工具使用和协调。”
通过捉迷藏,(1)追求者学会了追逐兽人,而逃逸者也得以逃脱(2)食者们学会了基本的工具使用方法-用箱子和墙壁建造堡垒。(3)搜寻者学会了使用坡道跳入藏身者的庇护所(4)藏身者学会了将坡道移到要建造堡垒的远处并将其锁定到位(5)寻找者学会了可以从锁定的坡道跳至箱子(6)藏匿者学会了在建造堡垒之前将未使用的盒子锁上。
这六种策略是随着代理人在捉迷藏中相互训练而出现的,每种新策略都为代理人进入下一阶段创造了以前不存在的压力,而没有任何直接诱因促使代理人与对象互动或探索。这些策略是多代理竞争和“捉迷藏”动力学引起的“自动课程”的结果。
该博客的作者说,他们了解到“代理商通常会以一种意想不到的方式找到利用您构建的环境或物理引擎的方法。”
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")