您现在的位置是:首页 >人工智能 > 2021-04-23 17:43:48 来源:
AdaSearch自适应搜索的连续消除方法
在机器学习的许多任务中,通常希望在给定固定的预先收集的数据集的情况下回答问题。但是,在某些应用中,我们没有先验数据; 相反,我们必须收集我们回答感兴趣的问题所需的数据。
例如,在环境污染物监测和人口普查式调查中出现这种情况。自己收集数据使我们能够将注意力集中在最相关的信息来源上。然而,确定哪些信息源将产生有用的测量可能是困难的。此外,当物理代理(例如机器人,卫星,人等)收集数据时,我们必须计划我们的测量,以便降低与代理的运动相关的成本。我们将这个抽象问题称为自适应感知。
我们引入了一种新的方法来体现自适应传感问题,其中机器人必须遍历其环境以识别感兴趣的位置或项目。自适应传感包括机器人技术中许多经过充分研究的问题,包括快速识别意外污染泄漏和放射源,以及在搜索和救援任务中找到个人。在这样的设置中,设计一个尽可能快地返回正确解决方案的传感轨迹通常是至关重要的。
我们关注放射源寻找(RSS)问题,其中无人机必须在其环境中识别最大放射性发射体,其中是用户定义的参数。RSS是自适应传感问题的一个特别有趣的例子,由于高度异质的背景噪声所带来的挑战,以及适合于统计置信区间的构建的良好表征的传感器模型的存在。
我们介绍了AdaSearch,一个用于一般自适应传感问题的连续消除框架,并在放射源搜索的背景下进行演示。AdaSearch明确保持环境中每个点的排放率的置信区间。使用这些置信区间,算法迭代地识别可能在顶部发射器中的一组候选点,并消除其他点。
体验式搜索作为多重假设检验场景
传统上,机器人社区已经将具体搜索设想为连续运动规划问题,其中机器人必须平衡探索其环境与选择有效轨迹。这推动了将轨迹优化和探索结合到单个目标中的方法,其可以使用后退水平控制进行优化(Hoffman和Tomlin,Bai等人,Marchant和Ramos)。相反,我们考虑一种替代方法,其中我们通过假设检验将问题表述为顺序最佳行为识别之一。
在顺序假设检验中,目标是通过迭代收集数据来得出许多单独问题的结论。给代理一组测量动作,每个动作根据不同的固定分布产生观察。ñ
代理人的目标是学习这观察分布的一些预先指定的属性。例如,在统计“A / B测试”中,测量动作对应于向新客户显示产品A或产品B,并记录他们对该产品的评估。这里,ññ= 2因为只有两个动作,显示产品A并显示产品B.感兴趣的属性是平均优选的产品(下图中的B)。当我们收集偏好的测量值时,我们会跟踪样本平均值以及它们周围的置信区间,由每个产品的置信区间(LCB)和置信区间上限(UCB)描述。随着我们收集更多测量值,我们对每个产品的偏好估计值更加自信,因此我们对产品之间的排名也更有信心。这表明产品B优于产品A的结论条件:如果产品B的LCB大于产品A的UCB,那么我们可以得出结论,概率很高,B平均优选为A.
在环境感测的背景下,每个动作可以对应于从给定位置和方向获取传感器读数。通常,代理希望知道哪个单一测量动作产生具有最大平均观测信号的观测值,或者哪组动作一起具有最大平均观测值。为此,代理可以使用先前测量的观察顺序地选择动作以支持将用于辨别具有最大平均观察的动作的最具信息性的未来动作。ķ
乍一看,顺序最佳动作识别可能看起来过于抽象,无法在移动的,具体的传感代理中使用。实际上,代理可以选择任意任意的测量动作序列,而不考虑潜在的成本 - 例如与改变动作相关的移动时间。然而,顺序最佳行动识别的抽象性质也是其最强大的力量。通过以精确的统计语言制定具体的搜索问题,我们开发关于与每个感测动作相关联的观察装置的可操作的置信区间,并确定在感兴趣的点可以自信地确定之前仍然需要采取的所有动作的集合。
我们提出的具体搜索方法AdaSearch使用来自顺序最佳动作识别和全局轨迹规划启发式的置信区间来实现渐近最优的测量复杂度,并有效地摊销运动成本。
放射源寻求
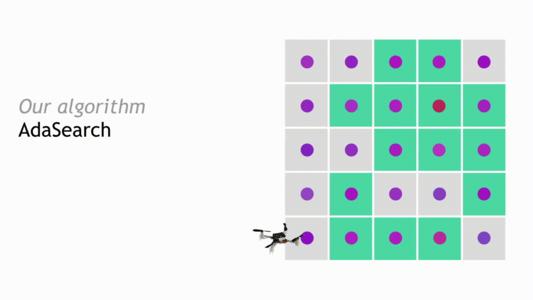
具体而言,我们将在单一来源的放射源寻求问题的背景下呈现AdaSearch。我们将环境建模为平面网格,如下图所示。只有一个高强度放射性点源(红点)。然而,定位该光源是困难的,因为传感器测量被背景辐射(粉红色点)破坏。通过在网格上方飞行配备有辐射传感器的四旋翼飞行器来获得传感器测量值。目标是设计一系列轨迹,以便从机载传感器获得的测量值允许我们尽可能快地消除放射性点源与背景辐射源的歧义。
AdaSearch
我们的算法AdaSearch将全局覆盖规划方法与基于假设检验的自适应感知规则相结合,以定义这些轨迹。在第一次通过网格时,我们在环境中均匀地进行采样。
基线
对于一般自适应搜索问题,最流行的方法可能是信息最大化(Bourgault等人)。信息最大化方法根据信息理论标准在被认为有希望的位置收集测量值,并遵循后退水平策略来规划轨迹。我们将AdaSearch与针对辐射检测定制的信息最大化版本进行比较:InfoMax。
不幸的是,对于大型搜索空间,该方法的实时计算约束需要近似,例如规划范围和轨迹参数化的限制。这些近似可能会导致算法过于贪婪,并且花费太多时间来追踪虚假线索。
为了消除我们的统计置信区间和全局规划启发式(与InfoMax的信息度量和后退时间范围规划)的影响之间的歧义,我们实施了一个简单的全局规划方法NaiveSearch作为第二个基线。该方法均匀地对网格进行采样,在每个网格单元处花费相等的时间。
结果
我们实现了所有三种算法,并使用逼真的四旋翼动力学和模拟辐射传感器读数,在64 x 64米网格上以4米分辨率模拟了他们在问题上的十个随机实例化的性能。
在我们的实验中,我们观察到AdaSearch通常比NaiveSearch和InfoMax完成得更快。随着我们增加最大背景辐射水平,AdaSearch的运行时间与NaiveSearch运行时间的比率继续提高,这与全文中给出的理论界限相匹配。
")









")
")
")
")
")
")
")
")
")